Example: SN Light-Curve#
Here we will work through an example to show the power of caskade in simplifying the process of developing an analysis routine. We will use a mock highly simplified supernova light curve fitting problem as our example. In this we will start with a simple analysis where we fit each light curve image separately, then we will use caskade’s parameter linking to join the data into a single likelihood, finally we will use function pointers to fit a light curve model rather than individual brightnesses. At each stage we will se how caskade makes it easy to build on past work and how it keeps track of all the parameters for us. The power of caskade is that it makes the development process easier so we don’t need to rewrite code or redo work as our model of the problem grows in complexity!
import caskade as ck
import torch
from torch.autograd.functional import hessian
from torch import vmap
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from matplotlib.patches import Ellipse
from IPython.display import HTML
from scipy.optimize import minimize
import emcee
Below we define our Gaussian and Combined modules like before. Expand to see the details.
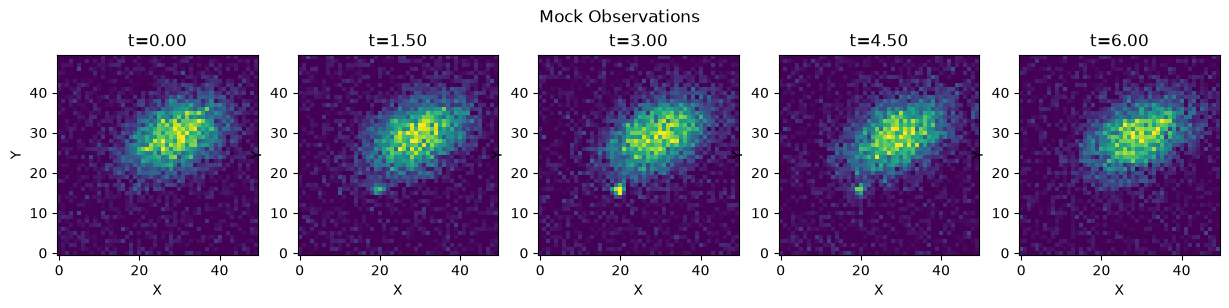
Making the mock data#
This has to be done first since that is what we will analyze, however you should skip this section and come back to it after you’ve read the rest!
Nobs = 5
imgsize = 50
sigma_read = 0.1
exp_time = 25
imgx, imgy = torch.meshgrid(
torch.linspace(-1, 1, imgsize), torch.linspace(-1, 1, imgsize), indexing="ij"
)
SN = Gaussian("SN", x0=[-0.35, -0.2], q=1.0, phi=0.0, sigma=0.05)
SN_lightcurve = Gaussian1D("lightcurve", t0=-3.0, sigma=2.0, peak_flux=0.25)
time = ck.Param("time")
SN.flux = lambda p: p.lightcurve.flux(p.time.value)
SN.flux.link((SN_lightcurve, time))
Galaxy = Gaussian("Galaxy", x0=[0.2, 0.2], q=0.6, phi=0.5, sigma=0.3, flux=1.0)
sim = Combined("sim", imgx, imgy, [SN, Galaxy])
Analysis starting point: Model each image individually#
Let’s imagine we are new to this problem and just starting out. We will make things simple and just analyze each image individually to construct our light curve. We are going to assume throughout that you know things like the read noise of your detector and the exposure time (which we are using as a basic noise model).
We will perform a straightforward likelihood analysis, thus our main goal will be to construct a likelihood.
class Likelihood(ck.Module):
def __init__(self, name, model, data, sigma_read=0.05, exp_time=25):
super().__init__(name)
self.model = model
self.data = data
self.sigma_read = sigma_read
self.exp_time = exp_time
@ck.forward
def residuals(self):
model_output = self.model()
variance = self.sigma_read**2 + model_output / self.exp_time
sigma = variance.sqrt()
residuals = (self.data - model_output) / sigma
return residuals, sigma
@ck.forward
def __call__(self): # log likelihood
residuals, sigma = self.residuals()
return -0.5 * (residuals**2).sum() - sigma.log().sum()
# Model
SNmodel = Gaussian("SN", x0=[-0.35, -0.2], q=1.0, phi=0.0, sigma=0.05, flux=0.2)
SNmodel.x0.to_dynamic() # "unknown" parameters
SNmodel.flux.to_dynamic()
Galaxymodel = Gaussian("Galaxy", x0=[0.2, 0.2], q=0.6, phi=0.5, sigma=0.3, flux=1.0)
Galaxymodel.to_dynamic() # "unknown" parameters
firstmodel = Combined("firstmodel", imgx, imgy, [SNmodel, Galaxymodel])
likelihood = Likelihood("likelihood", firstmodel, data[0], sigma_read=sigma_read, exp_time=exp_time)
likelihood.graphviz()

light_curve_flux = []
light_curve_sigma = []
model_images = []
model_residuals = []
# Analyze one image at a time with our likelihood model
for i in range(Nobs):
likelihood.data = data[i] # Update the data for each observation
# Fit the model
params = likelihood.get_values("array") # default is "array", we just added it for show
params += (
torch.randn_like(params) * params * 0.05
) # Add some noise to the initial guess since we cant start at the true values
res = minimize(lambda x: -likelihood(torch.tensor(x)).numpy(), params, method="Nelder-Mead")
light_curve_flux.append(res.x[2])
# Get uncertainty using inverse Hessian
hess = -hessian(likelihood, torch.tensor(res.x), strict=True)
hess_inv = torch.linalg.inv(hess)
light_curve_sigma.append(hess_inv[2, 2].abs().sqrt().item())
# Store model images and residuals
model_images.append(firstmodel(torch.tensor(res.x)).detach().numpy())
model_residuals.append(likelihood.residuals(torch.tensor(res.x))[0].detach().numpy())
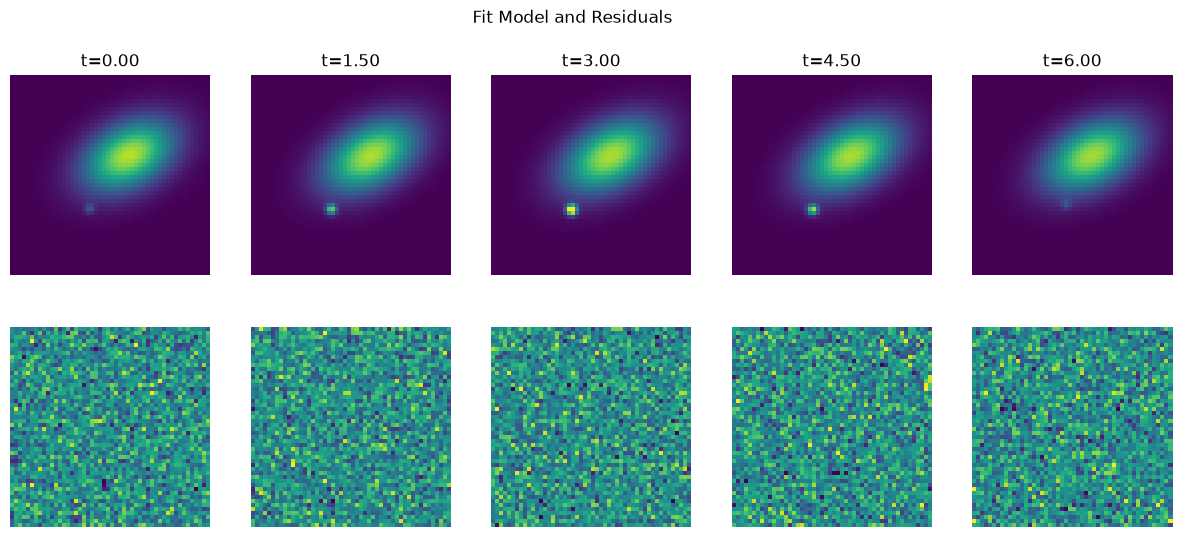
This is our first go at measuring the light curve. It mostly looks like what we should expect, the bright points are fit well but the faint ones fail and we get no meaningful flux estimate from them. For the very faint SN images, it is hard to see in the noise where the SN even is, let alone determine its flux. So next lets see if we can add some complexity to our model and get better results!
Analysis Improvement: Joint modelling#
We don’t need to analyze each image individually, we have some knowledge of how these SN should look in our data. For example, the position of the SN and galaxy should be constant with time, further, the galaxy should really be fixed over time, the only thing that changes is the SN flux, so lets encode that in our analysis.
caksade lets us fix parameters to match each other, so we will make a model for each image then link the parameters accordingly to the first image model. This way our parameter vector will only include what’s needed to model the full set of images. We also create a wrapper module to stack the results from all the models so it can easily be passed to the likelihood.
# One galaxy model since it does not change across images
Galaxymodel = Gaussian("Galaxy", x0=[0.2, 0.2], q=0.6, phi=0.5, sigma=0.3, flux=1.0)
Galaxymodel.to_dynamic() # "unknown" parameters
imgmodels = []
for i in range(Nobs):
SNmodel = Gaussian(f"SN{i}", x0=[-0.35, -0.2], q=1.0, phi=0.0, sigma=0.05, flux=0.2)
SNmodel.x0.to_dynamic() # "unknown" parameters
SNmodel.flux.to_dynamic()
imgmodel = Combined(f"image{i}", imgx, imgy, [SNmodel, Galaxymodel])
imgmodels.append(imgmodel)
if i > 0: # SN position doesnt change across images
SNmodel.x0 = imgmodels[0].models[0].x0
class Stack(ck.Module):
def __init__(self, name, models):
super().__init__(name)
self.models = models
@ck.forward
def __call__(self):
return torch.stack([model() for model in self.models], dim=0)
secondmodel = Stack("secondmodel", imgmodels)
likelihood2 = Likelihood("likelihood2", secondmodel, data, sigma_read=sigma_read, exp_time=exp_time)
likelihood2.graphviz()

# Fit light curve
params = likelihood2.get_values()
params += (
torch.randn_like(params) * params * 0.05
) # Add some noise to the initial guess since we cant start at the true values
res = minimize(lambda x: -likelihood2(torch.tensor(x)).numpy(), params, method="Nelder-Mead")
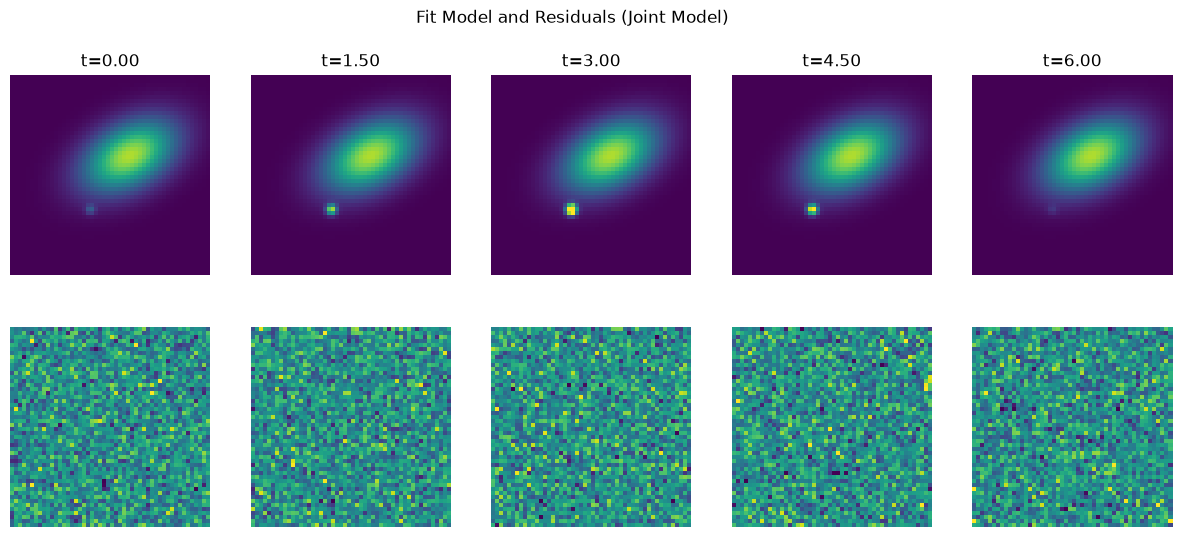
# extract light curve
likelihood2.set_values(torch.tensor(res.x))
likelihood2.to_static(children_only=False)
light_curve_flux = []
light_curve_sigma = []
for model in secondmodel.models:
light_curve_flux.append(model.models[0].flux.value.item())
model.models[0].flux.to_dynamic()
# Compute uncertainty using inverse Hessian
hess = -hessian(likelihood2, likelihood2.get_values(), strict=True)
hess_inv = torch.linalg.inv(hess) # Invert the Hessian to get the covariance matrix
light_curve_sigma = torch.sqrt(torch.diag(hess_inv)).numpy()
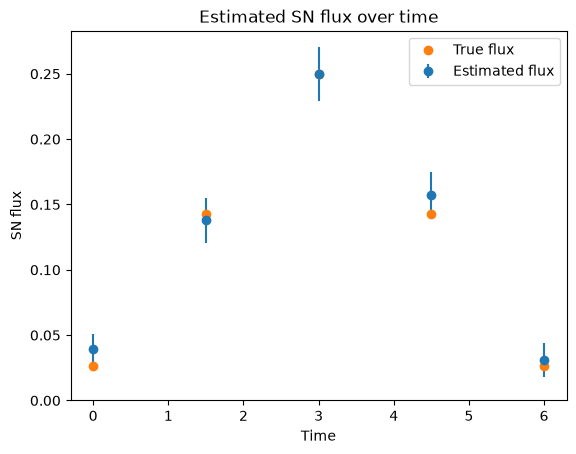
Estimated light curve fluxes: [0.04400048404932022, 0.16128379106521606, 0.3217029869556427, 0.20566445589065552, 0.016752654686570168]
Estimated light curve uncertainties: [0.0131262 0.01900692 0.02597192 0.02217101 0.01045672]
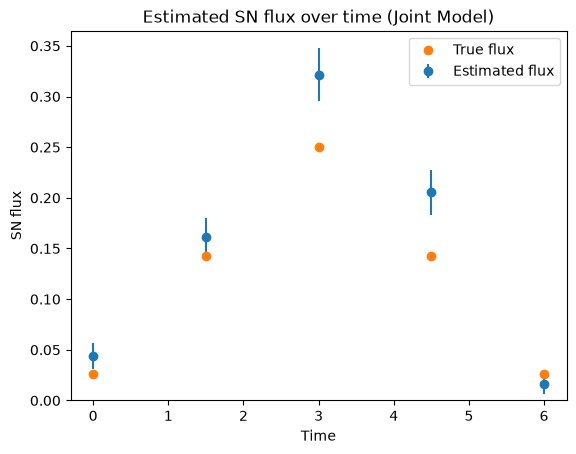
Clearly this is much more stable than fitting each image individually. The faint times of the SN lightcurve are very hard to find in the data, but using the position from the bright times we can lock it in so that we have a good position at all times, once the position is determined it is possible to measure the flux even though it is faint!
Analysis Improvement: Functional Light Curve#
We know the function for the light curve, it is a Gaussian in time (for this mock data at least), so we can encode that knowledge into our simulator by making the SN flux dependent on that function rather than a free parameter. What’s incredible is that we can simply reuse the previous model and tack on a new function of time to control the fluxes of the SN, no need to modify any of the previous code!
# Add light curve model to control the fluxes
lightcurvemodel = Gaussian1D("lightcurvemodel", t0=-3.0, sigma=2.5, peak_flux=0.25)
lightcurvemodel.to_dynamic()
for i in range(Nobs):
secondmodel.models[i].models[0].flux = lambda p: p.lightcurvemodel.flux(t=p.eval_t)
secondmodel.models[i].models[0].flux.link(lightcurvemodel)
secondmodel.models[i].models[0].flux.eval_t = times[i].clone()
likelihood2.graphviz()

Take a moment to appreciate the complexity of this model despite very little work on our part or alteration of our original gaussian light model. For the supernovae, they all share a position but each flux is a function of a light curve model evaluated at different times. We fixed the sigma for the SN assuming we knew the PSF but we could just as easily set it to dynamic and now we would be fitting the PSF width alongside all the other parameters! The galaxy is more straightforward, since all parameters are held constant, but consider that we didn’t need to modify our gaussian or likelihood code to enforce this, we did it by linking parameters, so we didn’t need to rewrite our likelihood or gaussian models and could reuse them for other models/projects!
# Fit light curve
params = likelihood2.get_values()
params += (
torch.randn_like(params) * params * 0.05
) # Add some noise to the initial guess since we cant start at the true values
res = minimize(lambda x: -likelihood2(torch.tensor(x)).numpy(), params, method="Nelder-Mead")
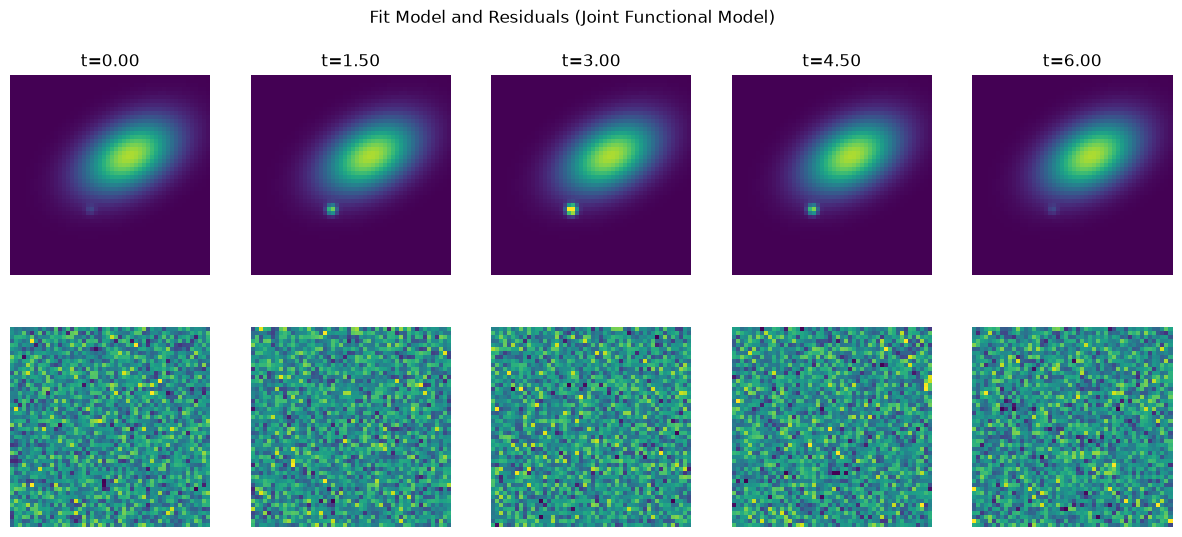
# extract light curve
likelihood2.set_values(torch.tensor(res.x))
light_curve_flux = []
light_curve_sigma = []
for model in secondmodel.models:
light_curve_flux.append(model.models[0].flux.value.item())
Estimated light curve fluxes: [0.02490910515189171, 0.14321139454841614, 0.25981247425079346, 0.14873236417770386, 0.026866678148508072]

Now we do even better! Since we know the form of the light curve, that gives us extra constraining power. Instead of fitting 5 fluxes, we now fit the three t0, sigma, peak_flux parameters and so we get even better results.
likelihood2.to_static(False)
lightcurvemodel.to_dynamic()
fit_vals = likelihood2.get_values()
hess = -hessian(likelihood2, fit_vals, strict=True)
hess_inv = torch.linalg.inv(hess).numpy() # Invert the Hessian to get the covariance matrix
light_curve_sigma = np.sqrt(np.abs(np.diag(hess_inv)))
print(
f"Light Curve t0: {fit_vals[0].item():.2f} ± {light_curve_sigma[0]:.2f} vs {SN_lightcurve.t0.value.item():.2f} (true)"
)
print(
f"Light Curve sigma: {fit_vals[1].item():.2f} ± {light_curve_sigma[1]:.2f} vs {SN_lightcurve.sigma.value.item():.2f} (true)"
)
print(
f"Light Curve peak flux: {fit_vals[2].item():.3f} ± {light_curve_sigma[2]:.3f} vs {SN_lightcurve.peak_flux.value.item():.3f} (true)"
)
Light Curve t0: -3.02 ± 0.09 vs -3.00 (true)
Light Curve sigma: 1.98 ± 0.12 vs 2.00 (true)
Light Curve peak flux: 0.260 ± 0.018 vs 0.250 (true)
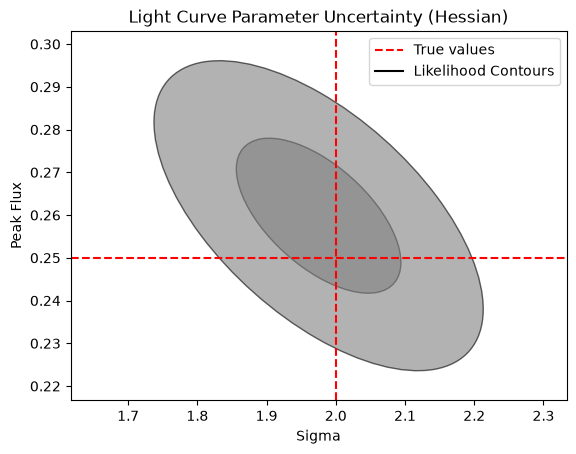
Performance improvement: Hierarchical modelling#
A primary goal of this tutorial is to demonstrate the features of caskade for linking parameters and building complex simulators. However, the model above is more complex than it needs to be. We have a separate model to represent the analysis of each image, which is somewhat wasteful given that all the images are the same size. This problem is asking us to use vmap to batch the analysis and therefore perform everything much more numerically efficiently.
Below is how one would actually analyze this problem with caskade.
class HierarchicalModel(ck.Module):
def __init__(self, name, SN: Gaussian, Galaxy: Gaussian, LightCurve: Gaussian1D, times):
super().__init__(name)
self.hierarchical_link("sn", SN)
self.galaxy = Galaxy
self.sn.lightcurve = LightCurve
self.data = data
self.times = times
@ck.forward
def get_sn_brightness(self, t):
self.sn.flux = self.sn.lightcurve.flux(t, ())
return self.sn.brightness(imgx, imgy, ())
@ck.forward
def __call__(self):
gal = self.galaxy.brightness(imgx, imgy)
sn = vmap(self.get_sn_brightness)(self.times)
return gal + sn
If you want to know more about the hierarchical_link used above or the to_static(None) used below, check out the Hierarchical Modelling Tutorial.
SNmodel = Gaussian("SN", x0=[-0.35, -0.2], q=1.0, phi=0.0, sigma=0.05)
SNmodel.flux.to_static(None) # make live param
SNmodel.x0.to_dynamic()
Galaxymodel = Gaussian("Galaxy", x0=[0.2, 0.2], q=0.6, phi=0.5, sigma=0.3, flux=1.0)
Galaxymodel.to_dynamic()
lightcurvemodel = Gaussian1D("lightcurvemodel", t0=-3.0, sigma=2.5, peak_flux=0.25)
lightcurvemodel.to_dynamic()
hierarchicalmodel = HierarchicalModel("hierarchical", SNmodel, Galaxymodel, lightcurvemodel, times)
likelihood3 = Likelihood(
"likelihood3", hierarchicalmodel, data, sigma_read=sigma_read, exp_time=exp_time
)
likelihood3.graphviz()

Now we have a likelihood and we can run everything just like before, except that it will all be much more efficient now. Instead of just rerunning an identical analysis, lets try something more computationally intensive, a full MCMC sampling of the likelihood. caskade turns our simulator and likelihood into simple functions of a 1D vector, we can use other packages besides scipy.optimize.minimize to analyze our data now. Here we try the emcee package for MCMC sampling.
vsim = torch.vmap(likelihood3)
# Log-likelihood function
def density(x):
return vsim(torch.as_tensor(x, dtype=torch.float32)).numpy()
params = likelihood3.get_values()
nwalkers = 32
ndim = len(params)
sampler = emcee.EnsembleSampler(nwalkers, ndim, density, vectorize=True)
params = params * (1 + 0.1 * torch.randn(nwalkers, ndim, dtype=torch.float32))
print("burn-in")
state = sampler.run_mcmc(params, 100, skip_initial_state_check=True) # burn-in
sampler.reset()
print("production")
state = sampler.run_mcmc(state, 1000) # production
burn-in
production
For reference, on my laptop at least, likelihood3 is about 3 times faster than likelihood2 despite them describing the same model. This is the advantage of batching.
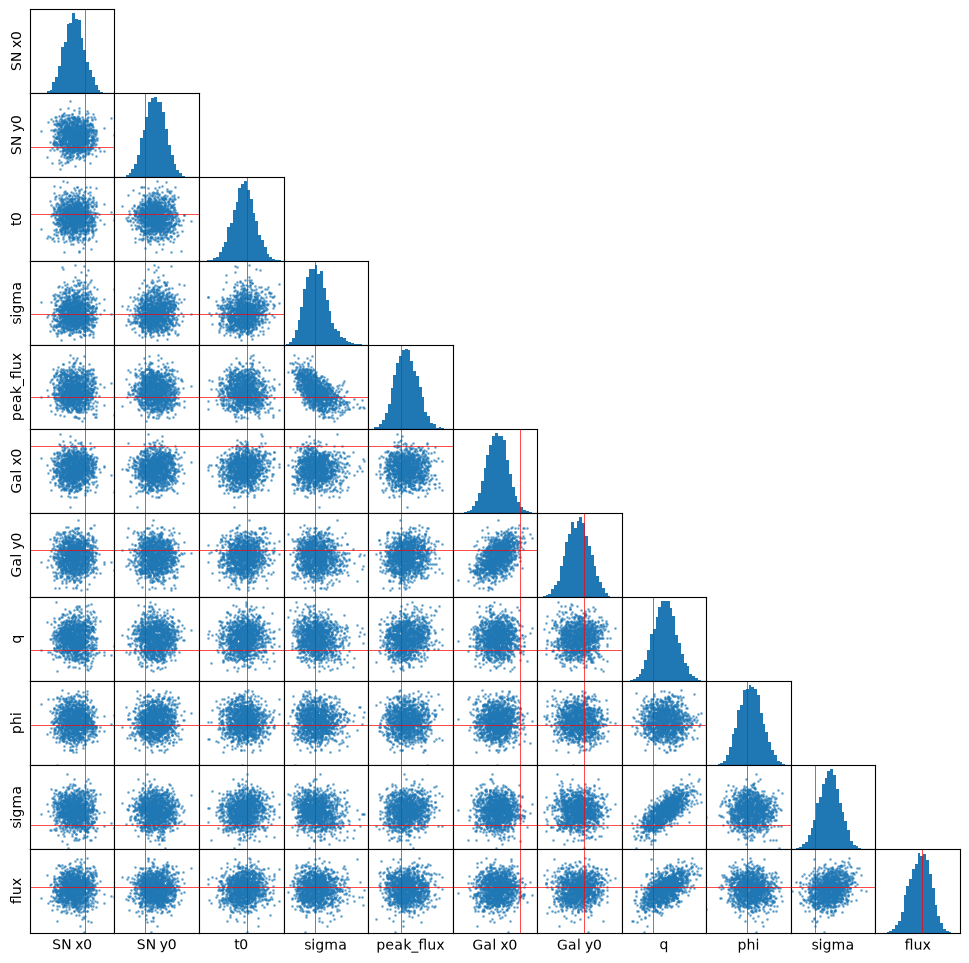
End note#
Now we are at the end you might think to yourself “wouldn’t it have been easier to just write the final model directly rather than using caskade?” And in a sense you are right. One could probably sit down and write this model out as a single class or a small series of functions. The problem is that science is an iterative process and you will likely not begin your project by simply sitting down and writing a complete model of every feature in your data. You will experiment, and break things, and increase complexity, and backtrack, and change goals, and so on as the project changes in scope and the objective becomes clearer. What caskade really accomplishes is letting you do all that iteration quickly, without re-writing each time, in a less error prone way, letting you see changes visually in the graph, and letting a project grow in scale naturally. caskade is built for the scientific development process, and those who use it don’t turn back.